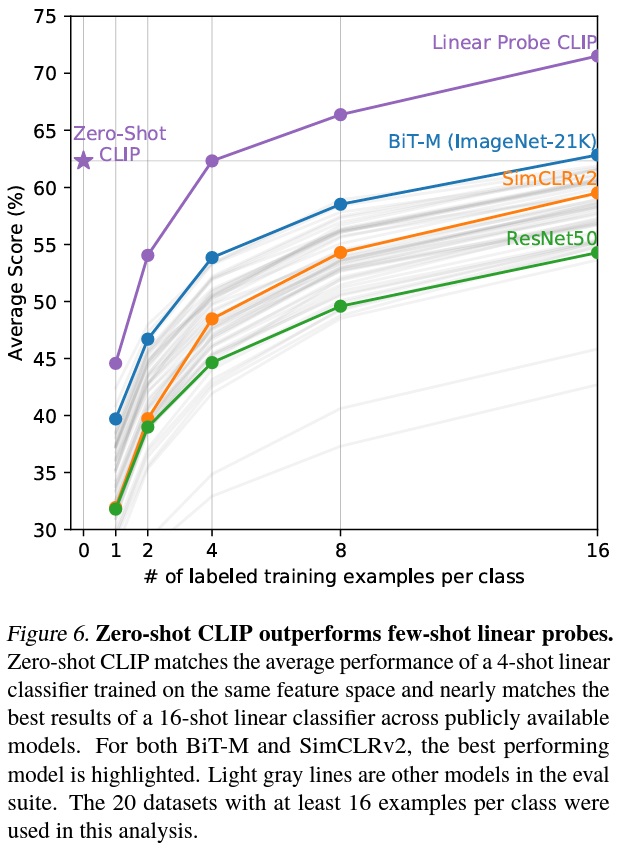
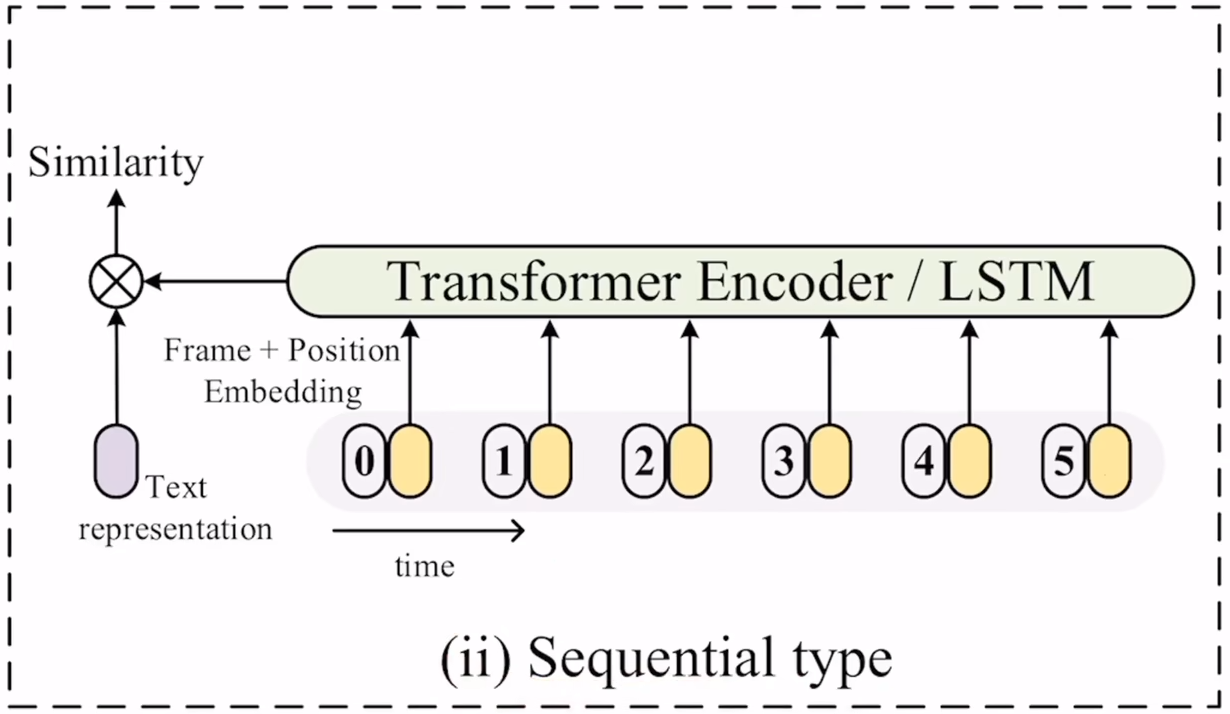
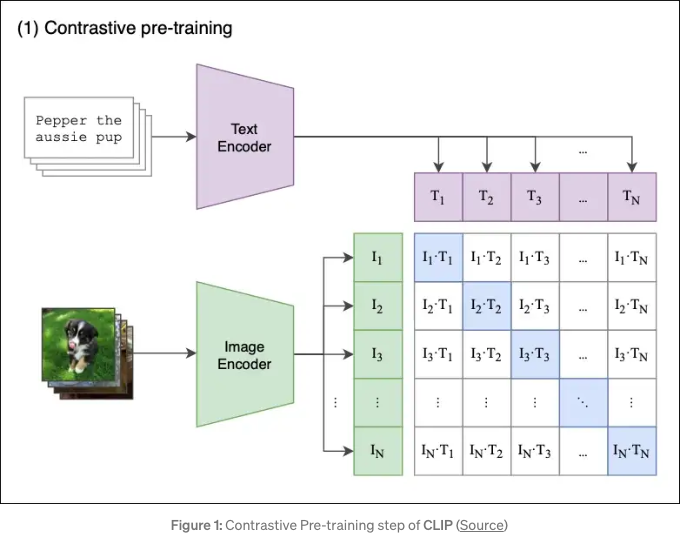
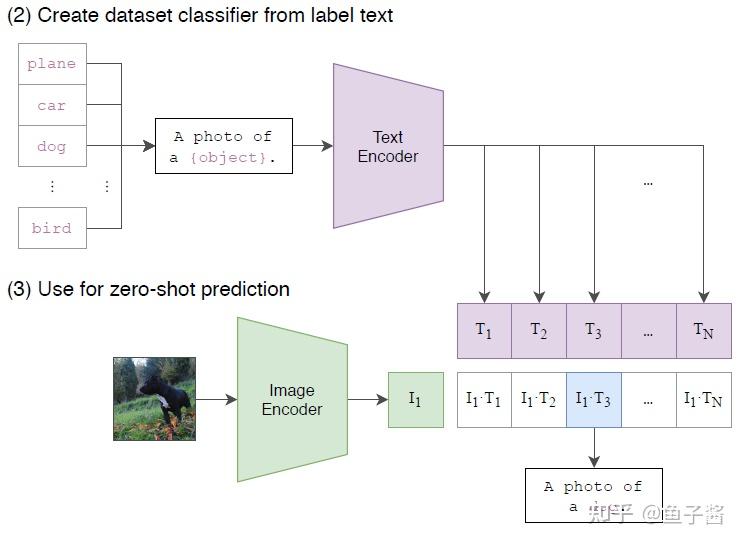
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
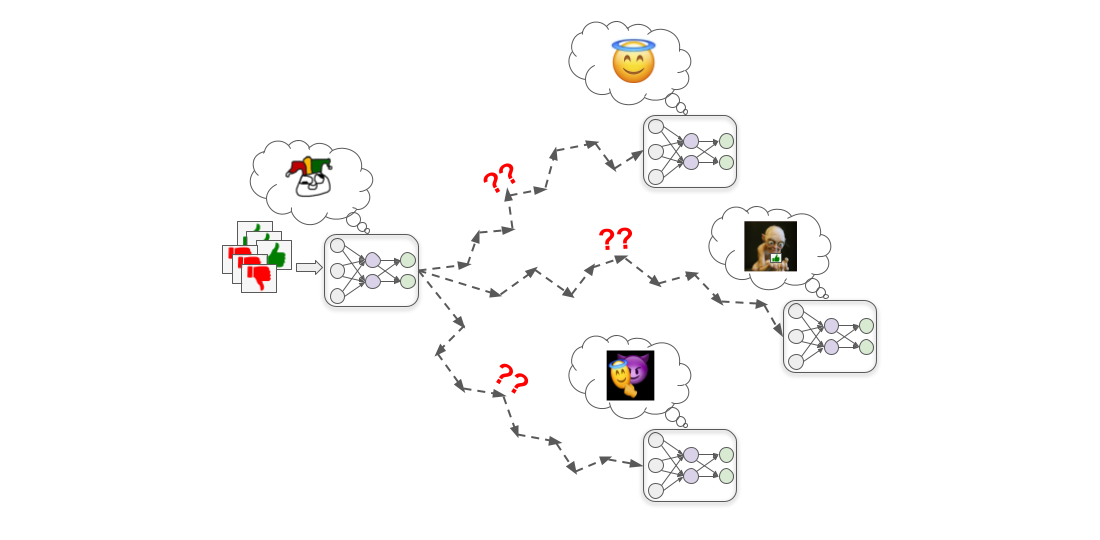
Alignment Calibration: Machine Unlearning for Contrastive Learning ...
What Is Alignment In Machine Learning at Adeline Zebrowski blog
ContextCLIP: Contextual Alignment of Image-Text pairs on CLIP visual ...
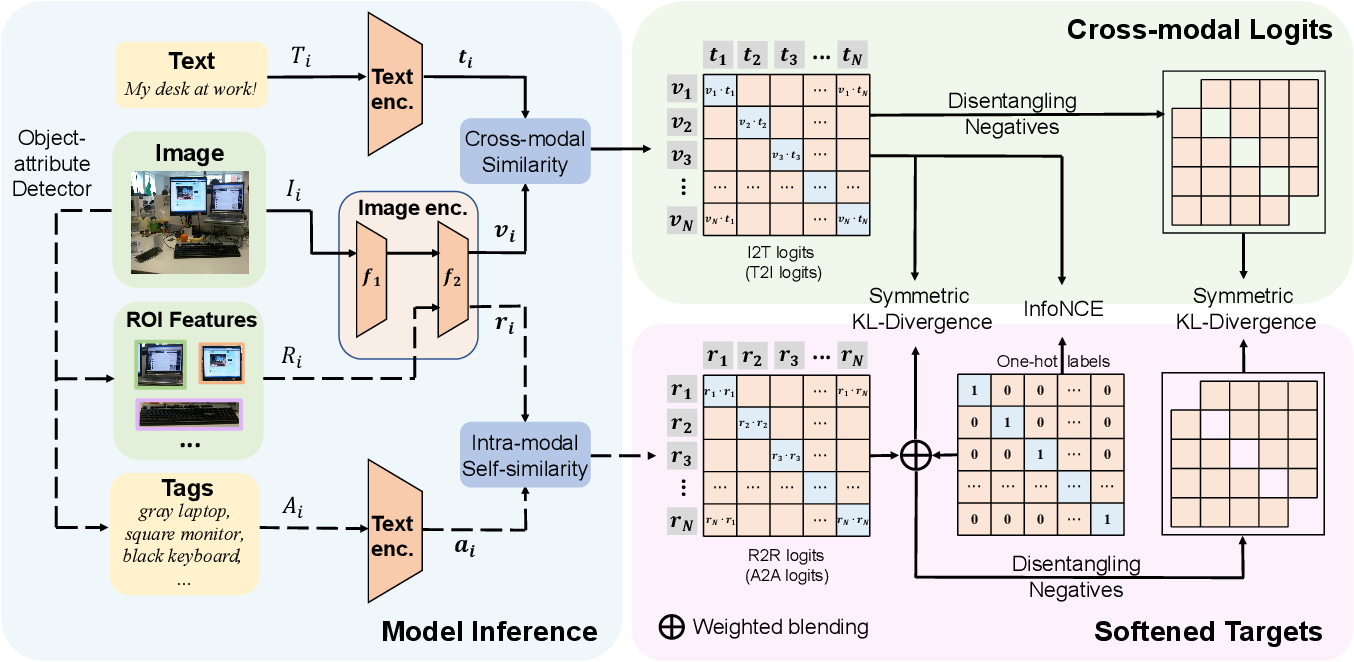
SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger - 知乎
Figure 1 from Cross-Modal Alignment Learning of Vision-Language ...
3D Shape Tokenization - Apple Machine Learning Research
Figure 3 from Bridging CLIP and StyleGAN through Latent Alignment for ...
Table 1 from Bridging CLIP and StyleGAN through Latent Alignment for ...
Why AI alignment could be hard with modern deep learning
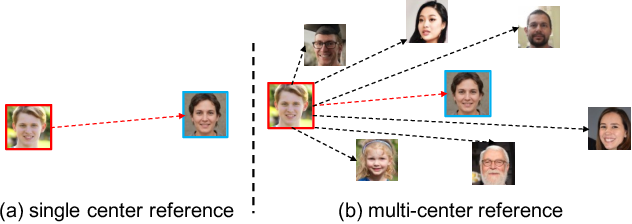
(PDF) ContextCLIP: Contextual Alignment of Image-Text pairs on CLIP ...
Figure 4 from Bridging CLIP and StyleGAN through Latent Alignment for ...
Figure 2 from SoftCLIP: Softer Cross-modal Alignment Makes CLIP ...
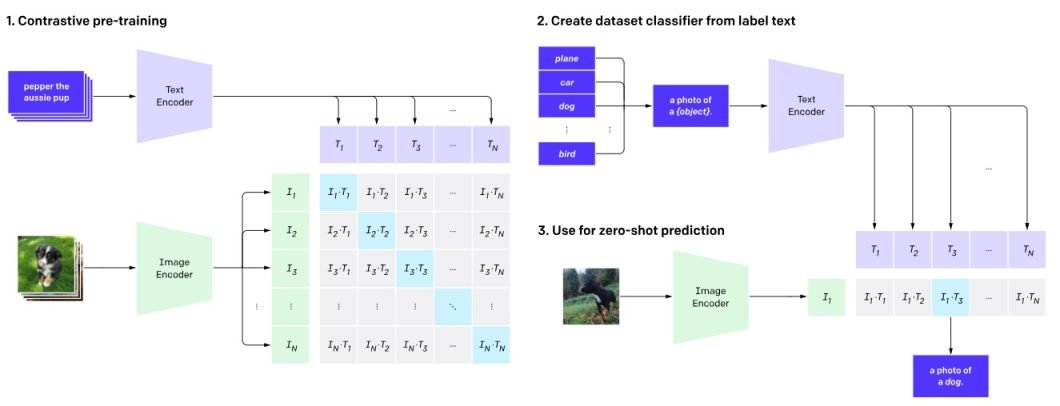
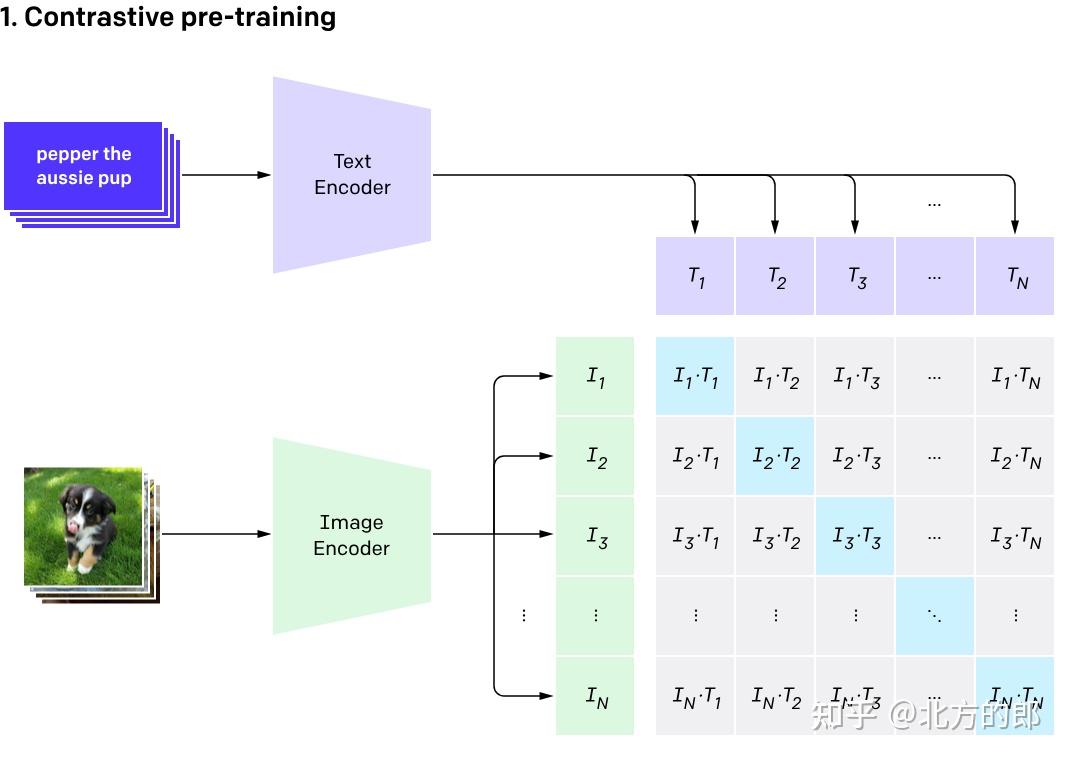
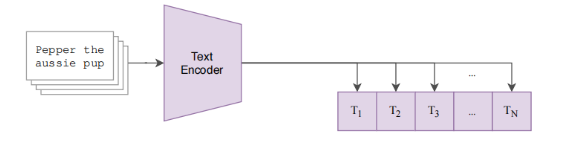
CLIP Learning Transferable Visual Models From Natural Language ...
Figure 1 from Bridging CLIP and StyleGAN through Latent Alignment for ...
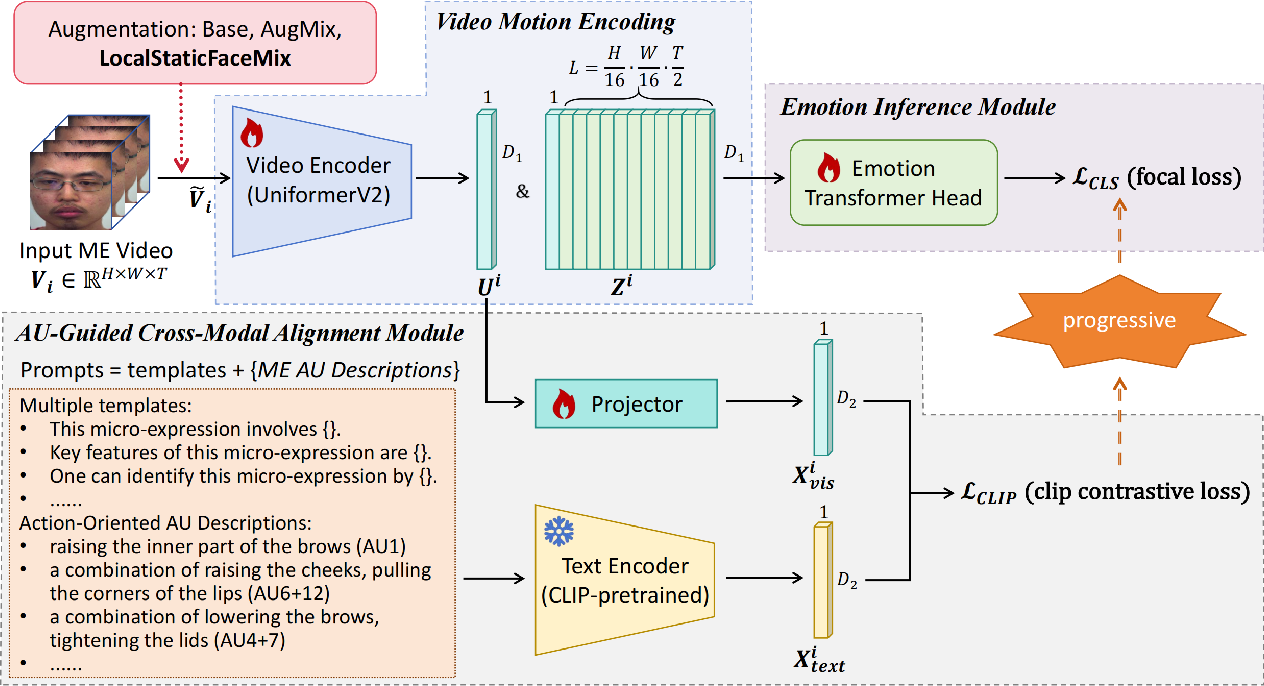
Figure 2 from MER-CLIP: AU-Guided Vision-Language Alignment for Micro ...
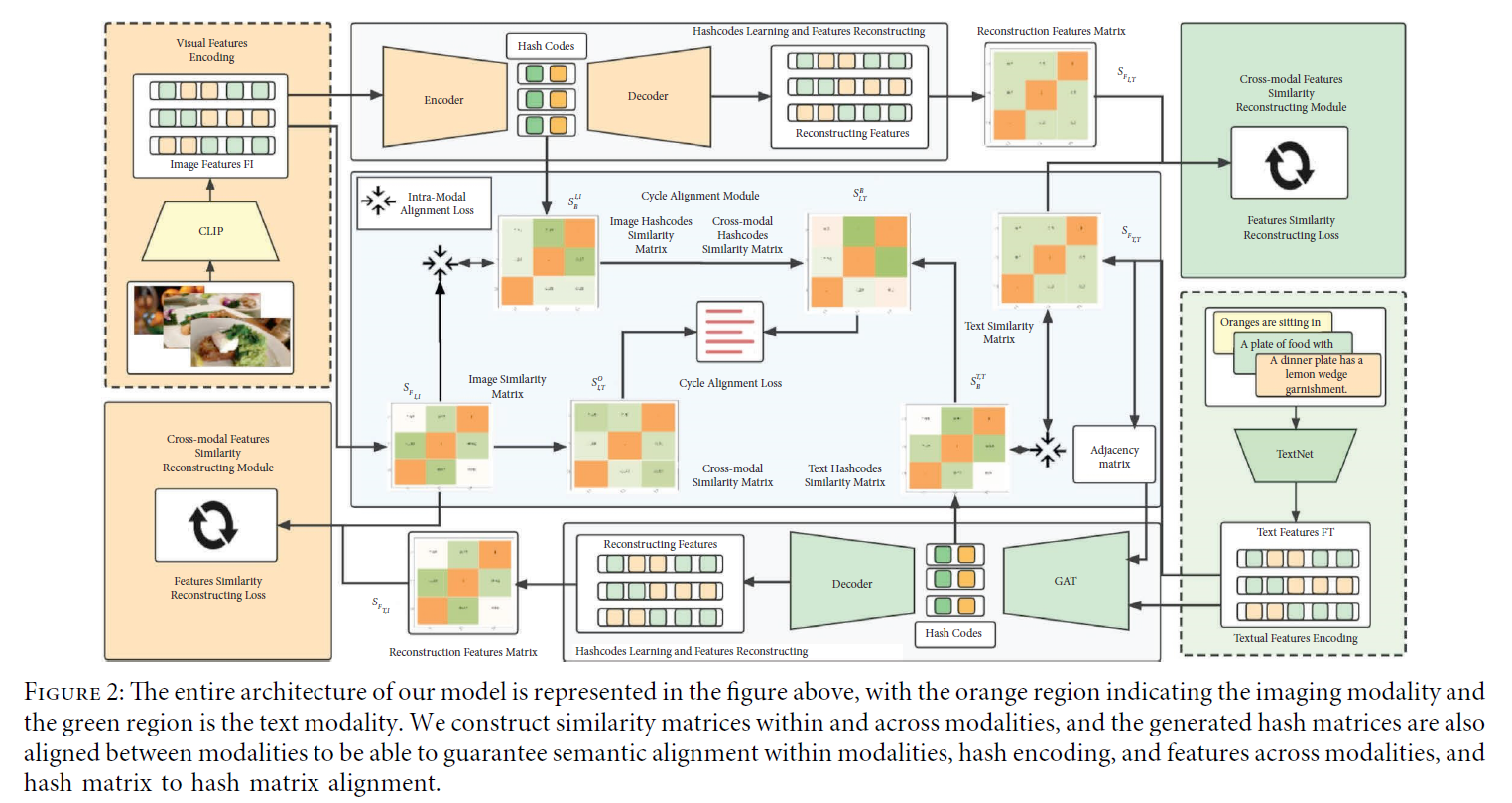
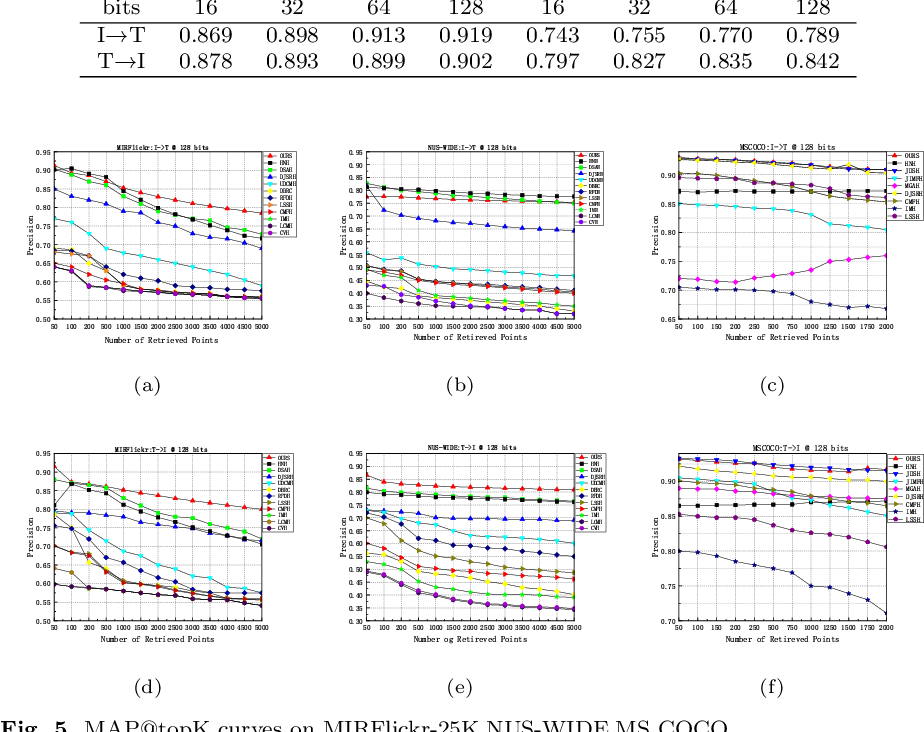
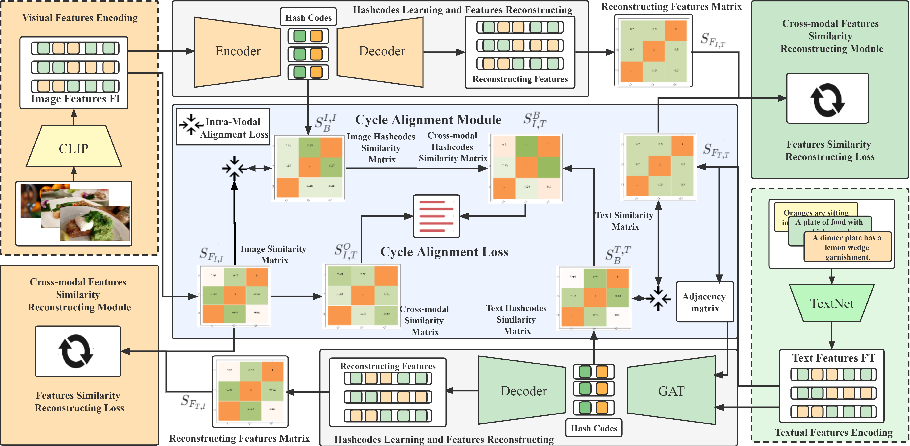
Figure 2 from CLIP-based Cycle Alignment Hashing for unsupervised ...
Revisiting CLIP: Efficient Alignment of 3D MRI and Tabular Data using ...
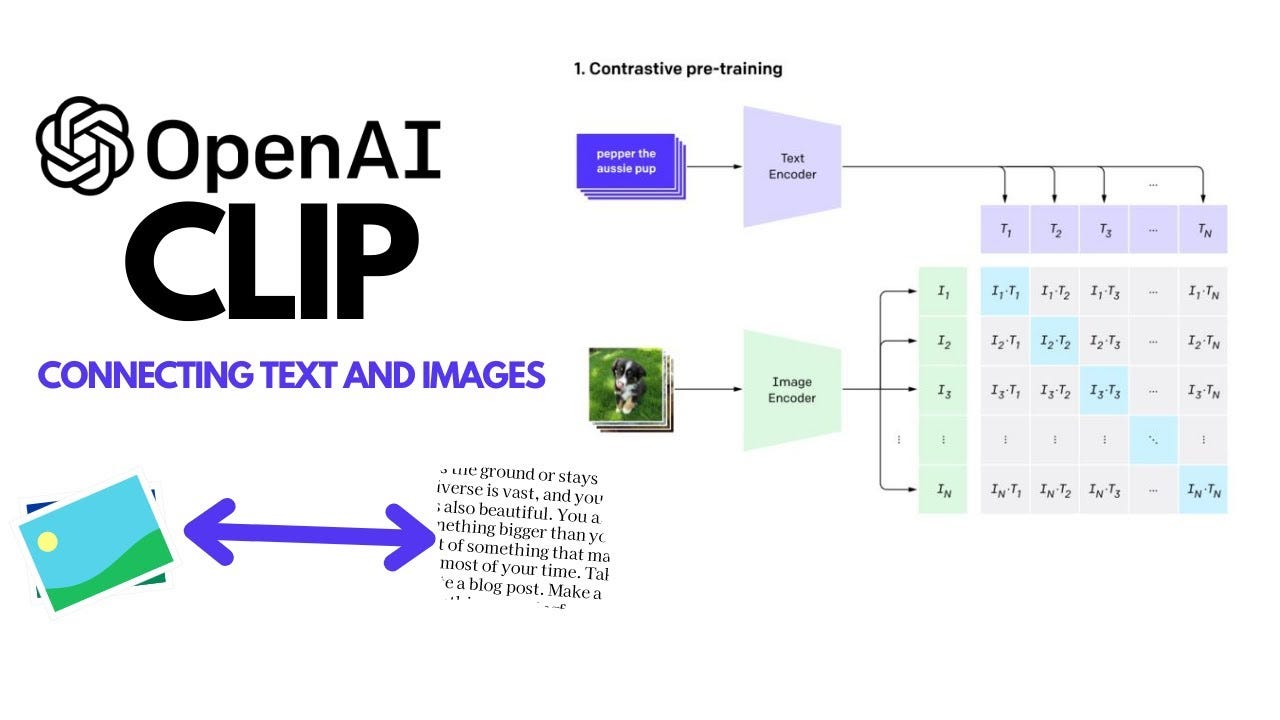
CLIP (Contrastive Language-Image Pretraining) - GeeksforGeeks
Multi Modal Fusion for Video Retrieval based on CLIP Guide Feature ...
Understanding CLIP for vision language models | by Frederik vom Lehn ...
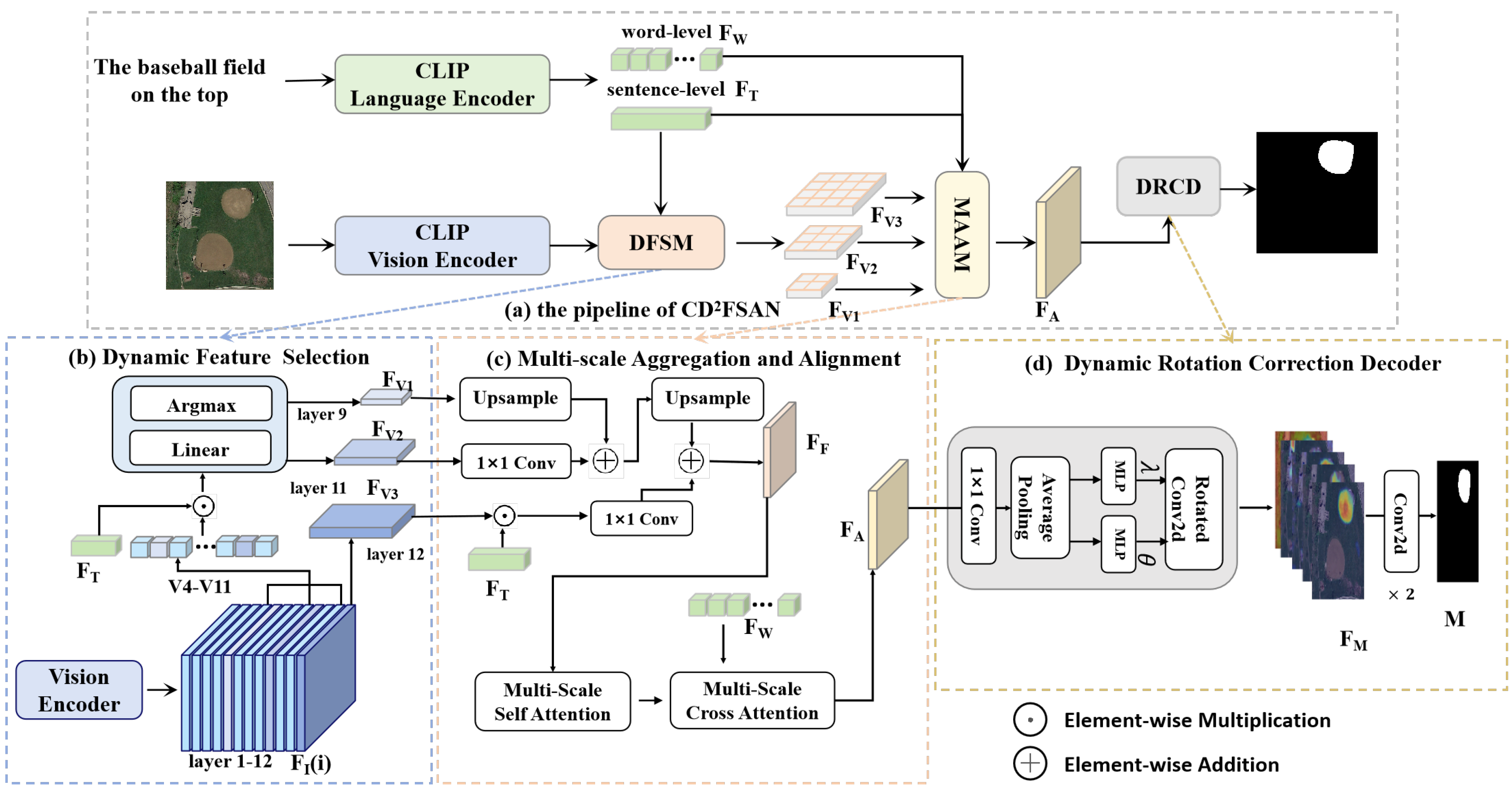
CLIP-Driven with Dynamic Feature Selection and Alignment Network for ...
FG-CLIP 2: A Bilingual Fine-grained Vision-Language Alignment Model ...
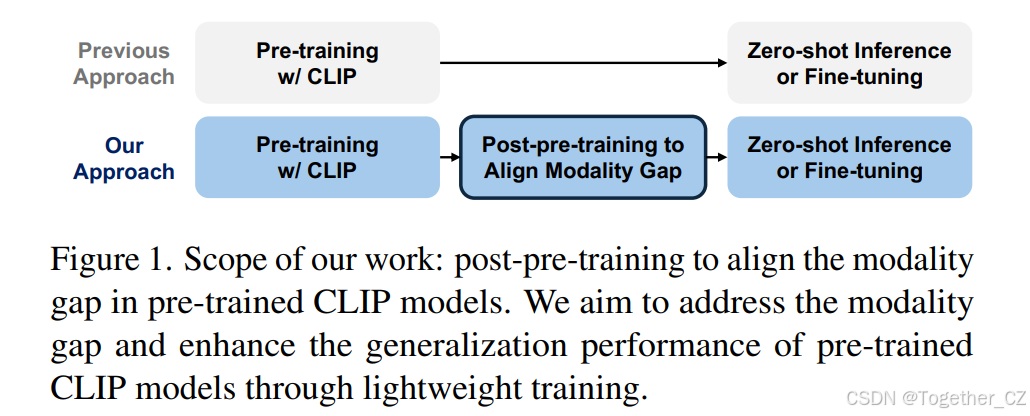
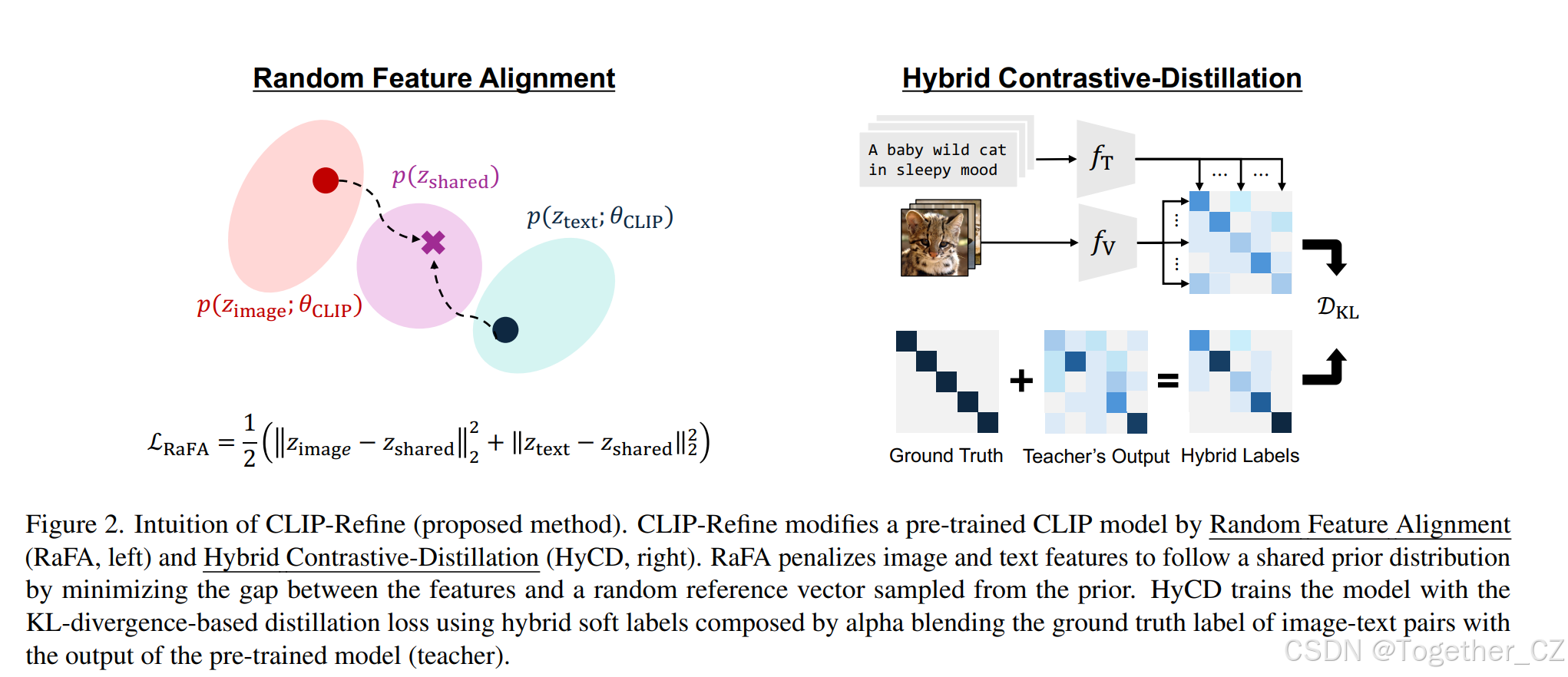
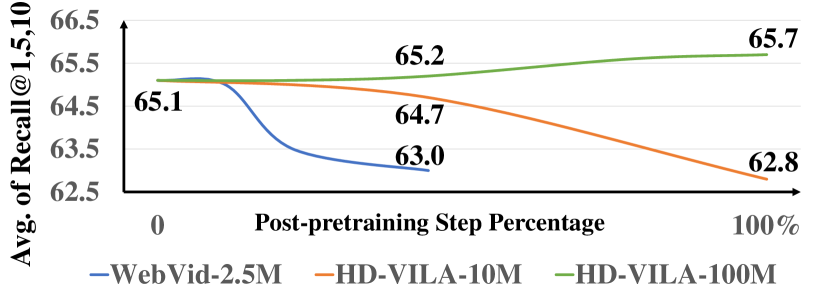
CLIP-Refine:Post-pre-training for Modality Alignment in Vision-Language ...
Discover How CLIP Bridges Text and Image Data
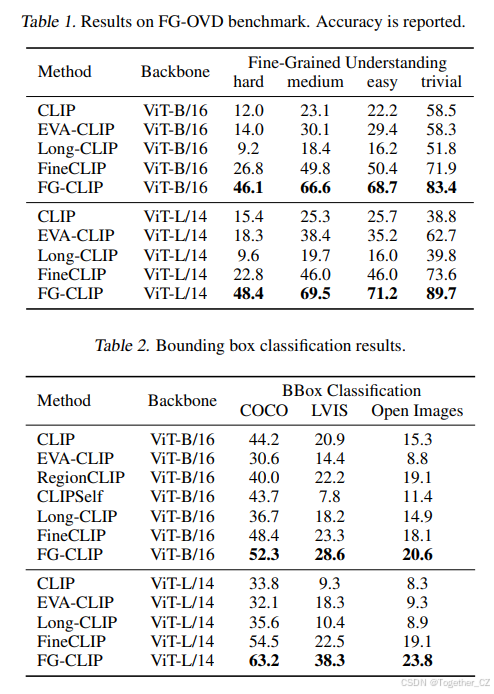
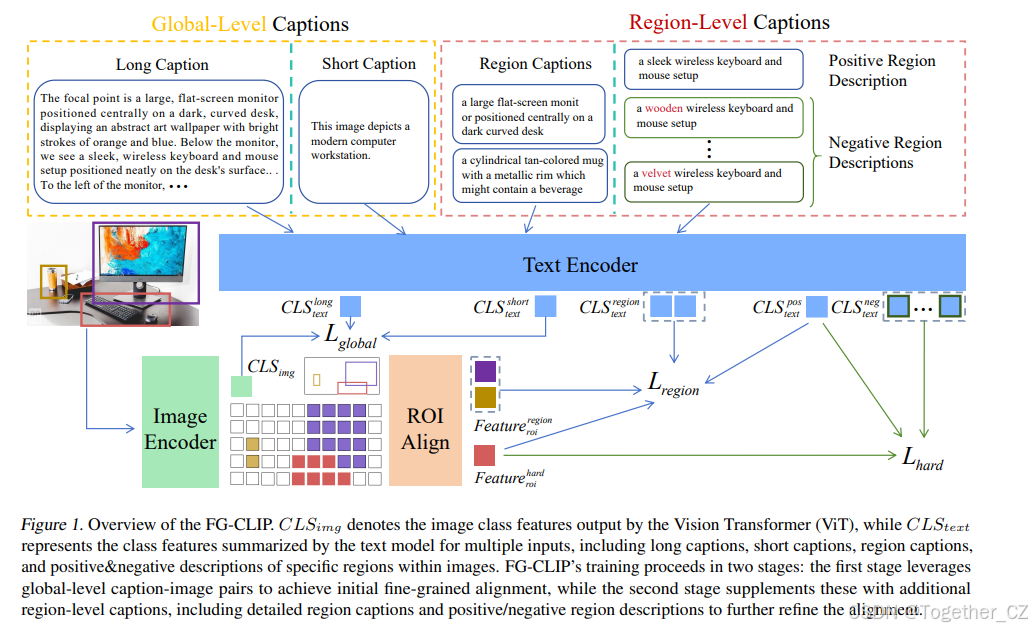
FG-CLIP: Fine-Grained Visual and Textual Alignment | AI Research Paper ...
Closing the Confusion Loop: CLIP-Guided Alignment for Source-Free ...
Figure 2 from How Much Can CLIP Benefit Vision-and-Language Tasks ...
Contrastive Alignment of Vision to Language Through Parameter-Efficient ...
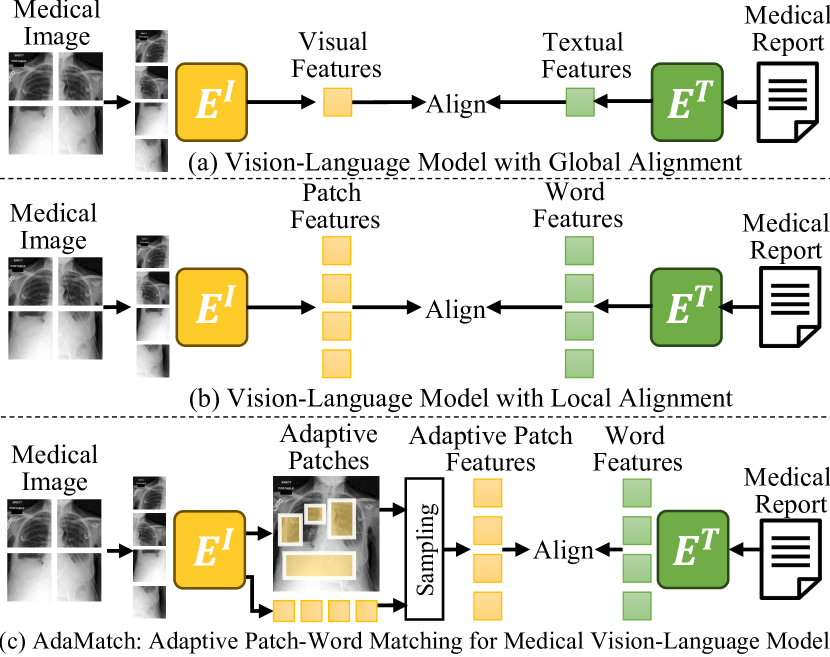
[2312.08078] Fine-Grained Image-Text Alignment in Medical Imaging ...
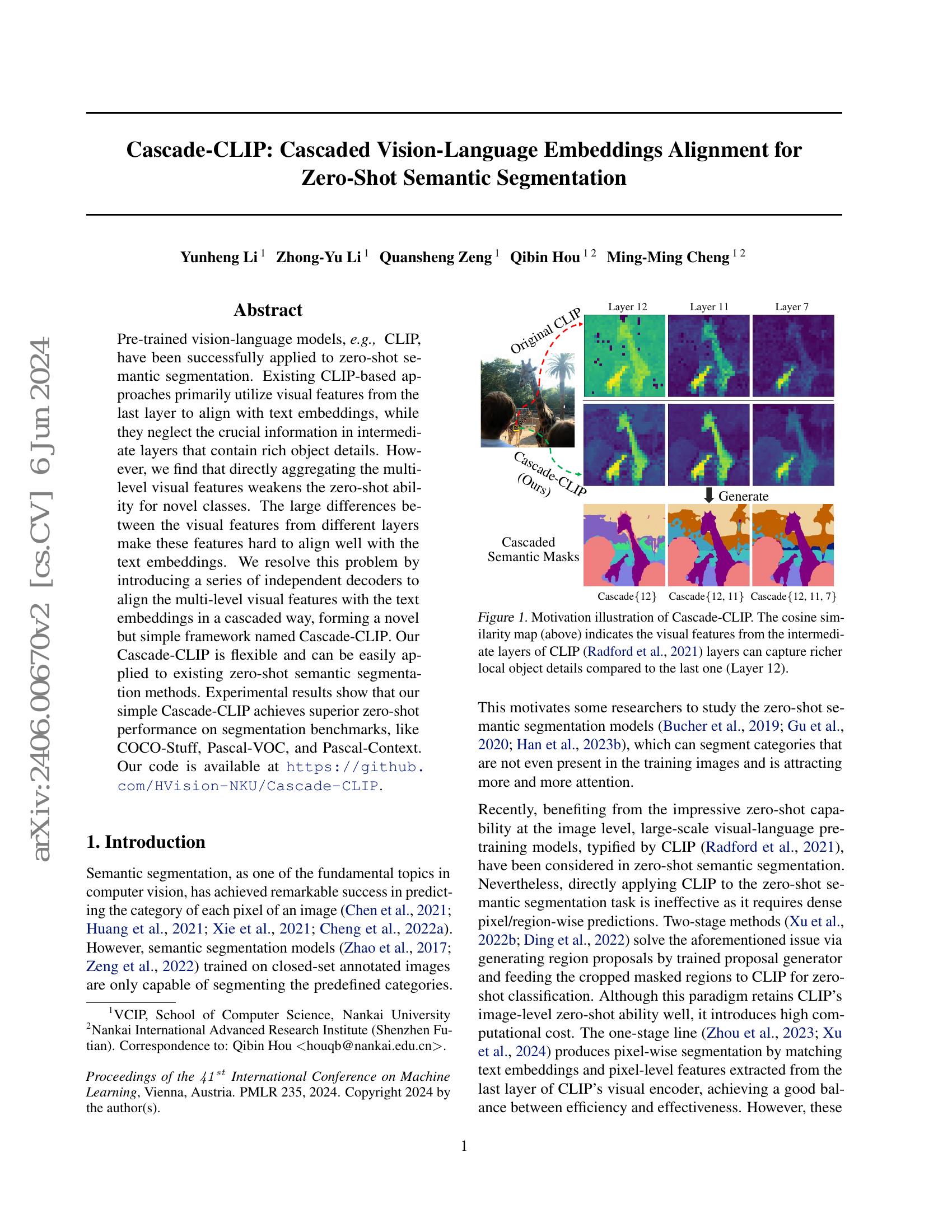
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero ...
(PDF) DC-CLIP: Multilingual CLIP Compression via vision-language ...
Deep Learning Models Connecting Images and Text: A Primer for ...
THMM-CLIP: Task-Guided Hierarchical Multi-Modal Alignment for Rehearsal ...
CLIPErase: Efficient Unlearning of Visual-Textual Associations in CLIP ...
Bridging the Gap Between Text and Images in Computer Vision With CLIP ...
CCAH: A CLIP-Based Cycle Alignment Hashing Method for Unsupervised ...
Building a CLIP-like Model for Image-Text Alignment From Scratch: A ...
Development of ML-based Optical Fine Alignment tool | PPTX
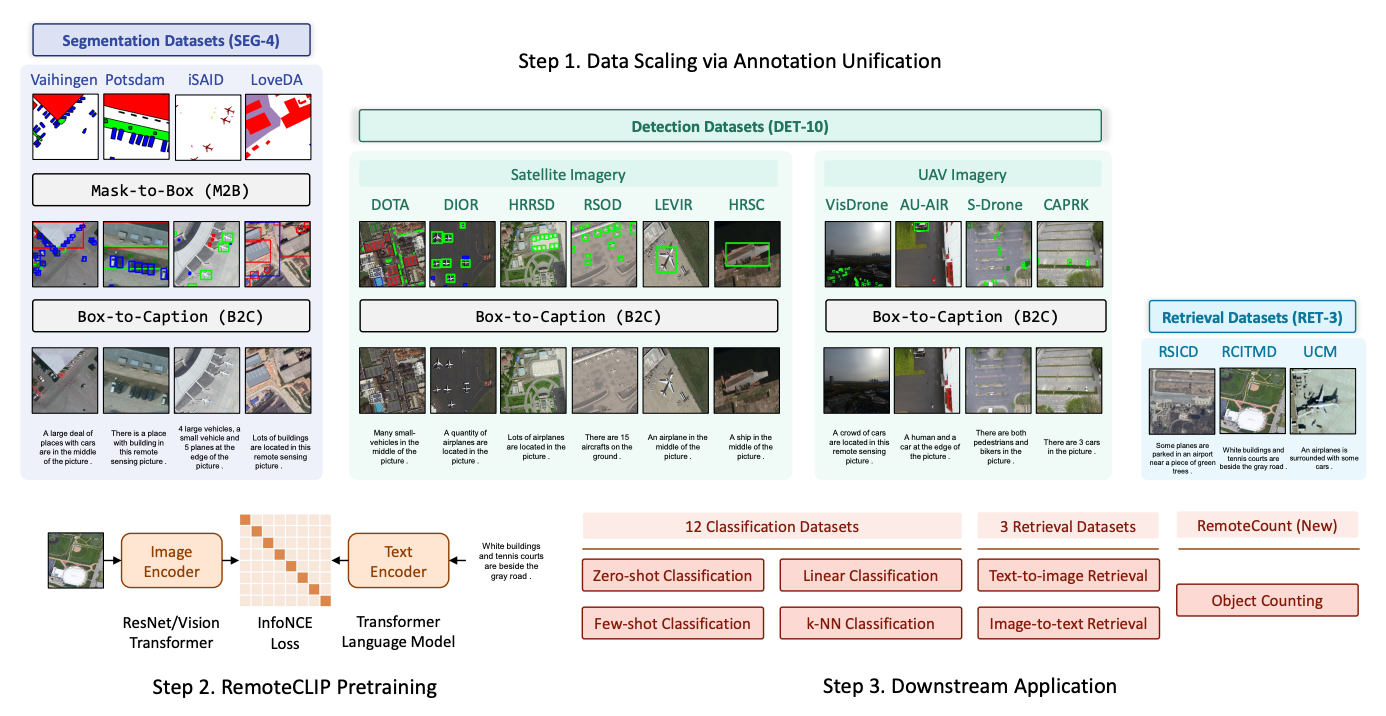
CVAF: A CLIP-Based View-Consistent Alignment Framework for Aerial ...
Coarse-to-fine Alignment Makes Better Speech-image Retrieval | AI ...
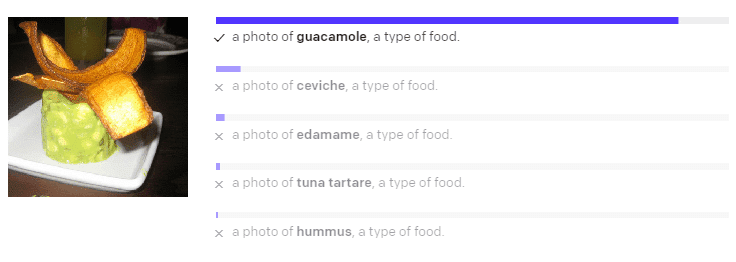
Zero-shot Image Classification with OpenAI's CLIP | Pinecone
MulCLIP: A Multi-level Alignment Framework for Enhancing Fine-grained ...
Example problem solution using CLIP algorithm. | Download Scientific ...
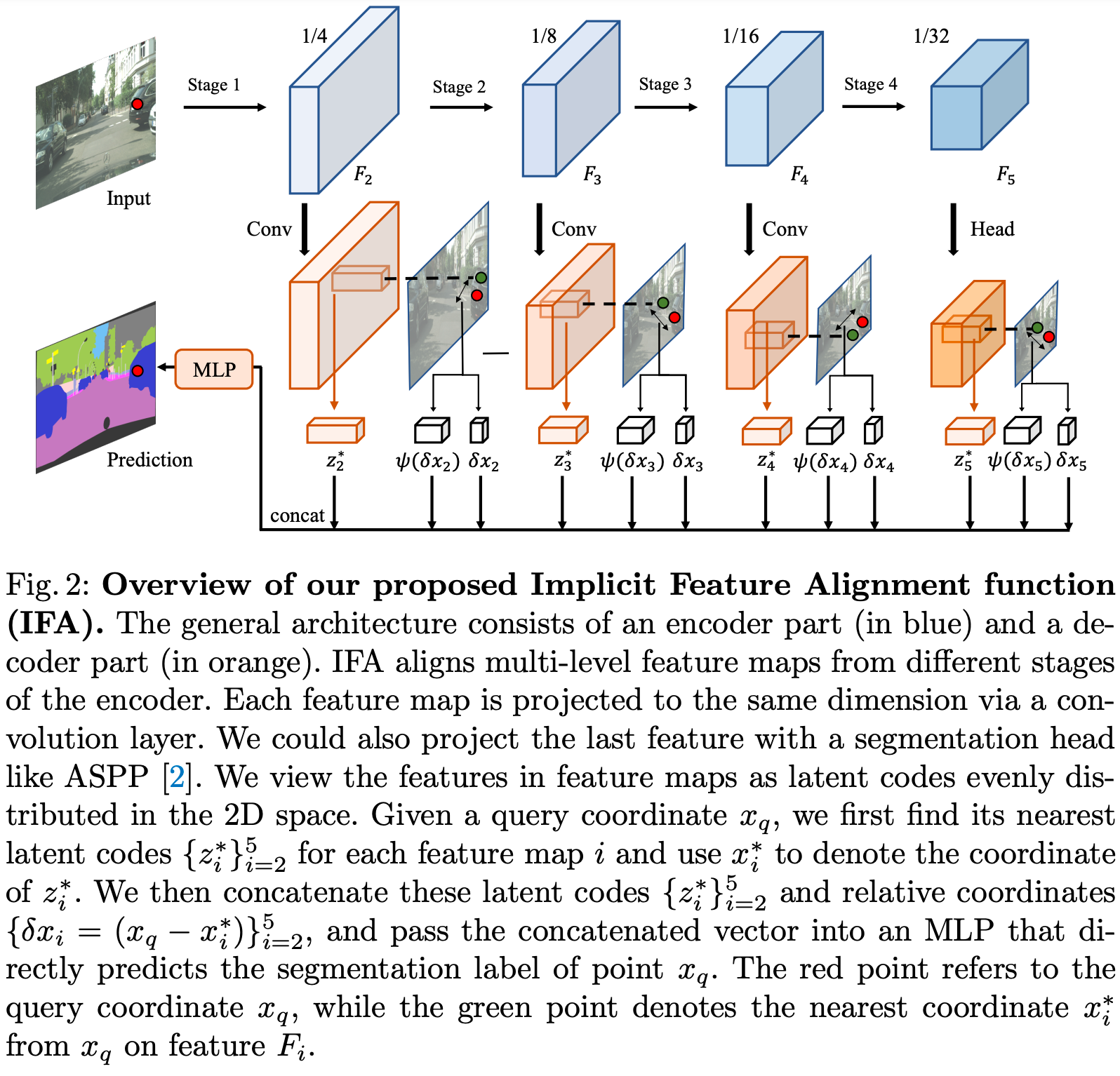
[ECCV2022]Learning Implicit Feature Alignment Function for Semantic ...
Mastering Machine Train Alignment: Best Practices for Every Job - Acoem USA
Figure 5 from CCAH: A CLIP-Based Cycle Alignment Hashing Method for ...
(PDF) CLIP-Driven with Dynamic Feature Selection and Alignment Network ...
[논문 리뷰] CURVE: CLIP-Utilized Reinforcement Learning for Visual Image ...
Lyrics: Boosting Fine-grained Language-Vision Alignment via Semantic ...
[논문 리뷰] Revisiting CLIP: Efficient Alignment of 3D MRI and Tabular Data ...
Figure 5 from CLIP-based Cycle Alignment Hashing for unsupervised ...
CLIP: Learning Transferable Visual Models From Natural Language ...
How to Modify OpenAI’s CLIP Model for Fine-Grained Classification | by ...
CLIP 改进工作串讲(下)学习笔记 - Lhiker - 博客园
(PDF) CLIP-based Cycle Alignment Hashing for unsupervised vision-text ...
(PDF) CCAH: A CLIP-Based Cycle Alignment Hashing Method for ...
Aman's AI Journal • Models • CLIP
【CLIP系列Paper解读】CLIP: Learning Transferable Visual Models From Natural ...
Extending CLIP’s Image-Text Alignment to Referring Image Segmentation ...
Review — CLIP: Learning Transferable Visual Models From Natural ...
[CLIP] Learning Tranferable Visual Model From Language Supervision 논문 리뷰
A Fine-Grained Semantic Alignment Method Specific to Aggregate Multi ...
Soft-clipping VS hard-clipping in read alignment | by Wenyu | Medium
(PDF) FineLIP: Extending CLIP's Reach via Fine-Grained Alignment with ...
[2211.07122] ContextCLIP: Contextual Alignment of Image-Text pairs on ...
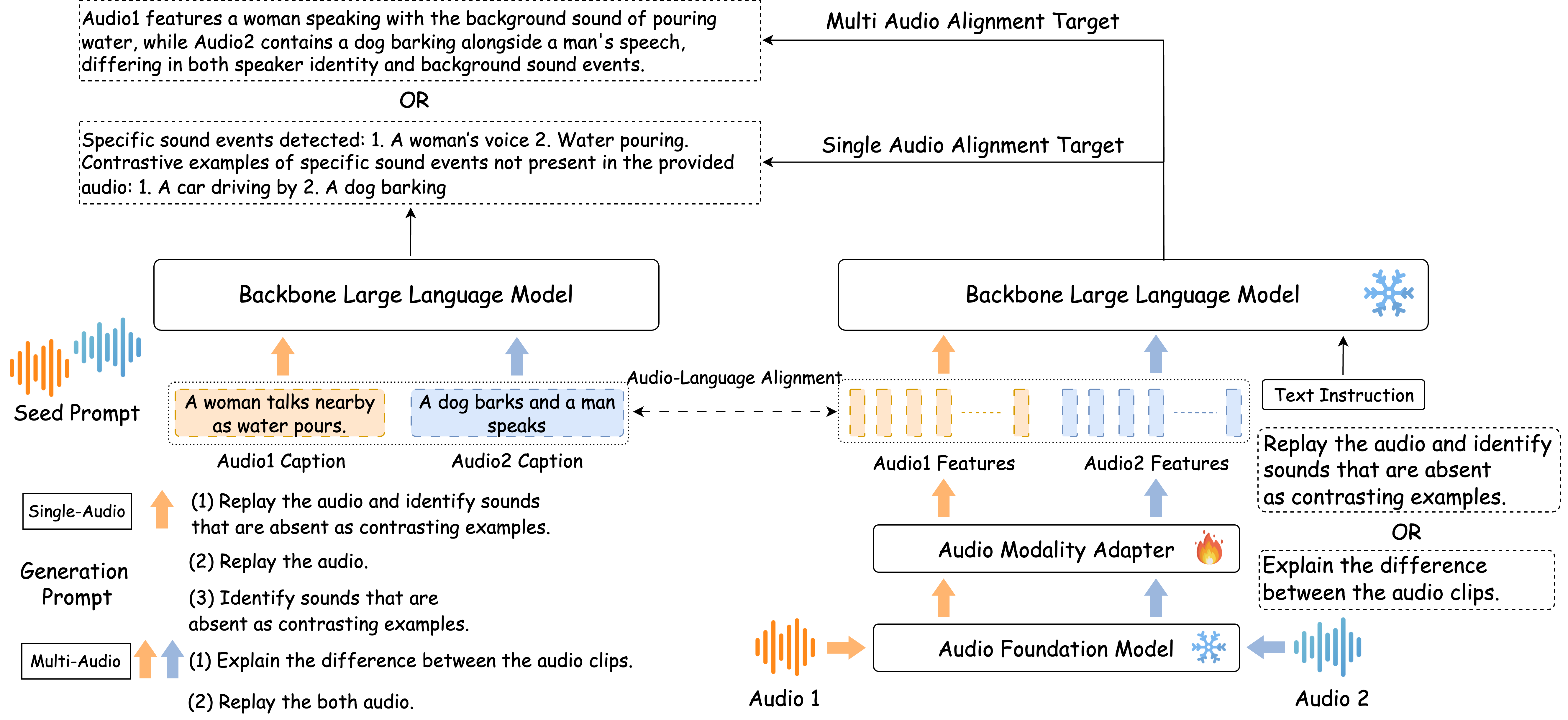
From Alignment to Advancement: Bootstrapping Audio-Language Alignment ...
Finetune clip with HuggingFace | by Kevork Sulahian | Medium
Fine-Grained Image-Text Alignment in Medical Imaging Enables ...
Exploring Fine-Grained Image-Text Alignment for Referring Remote ...
Boosting Medical Visual Understanding From Multi-Granular Language ...
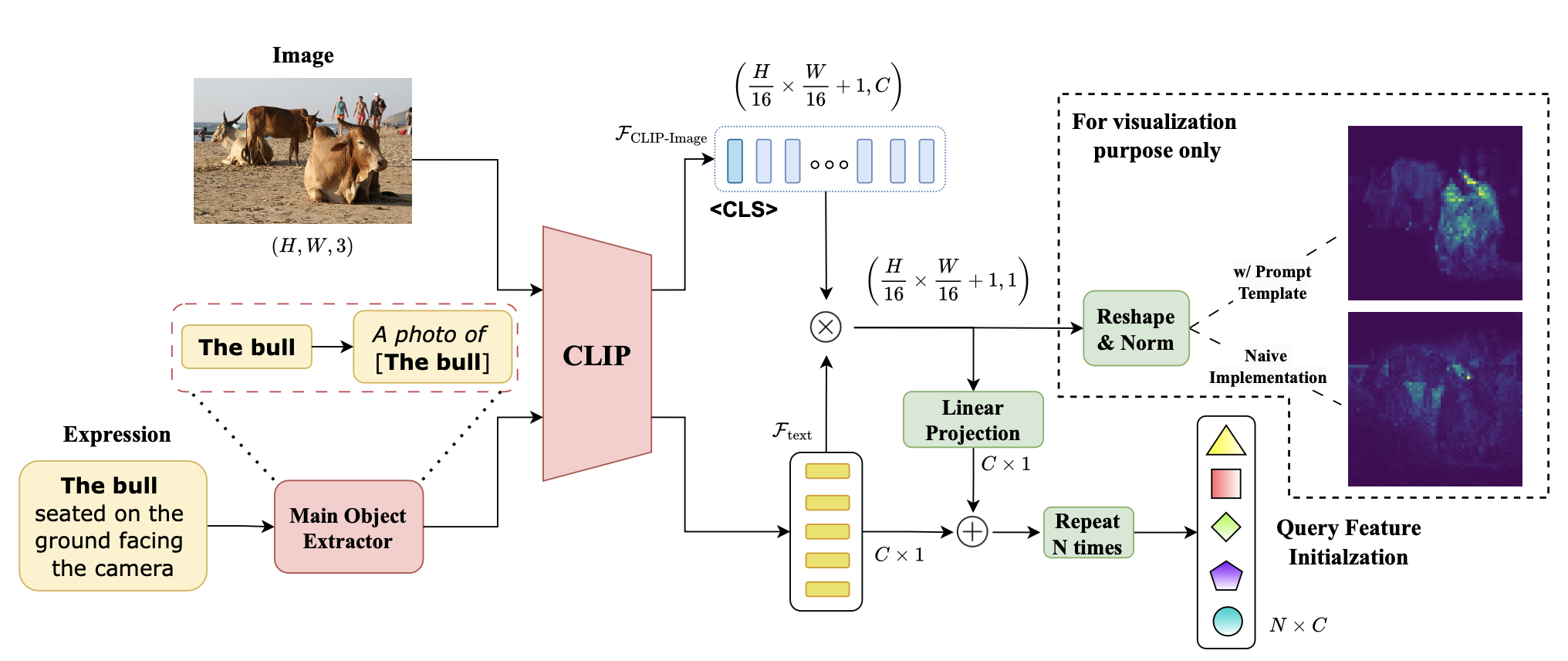
Vision-Aware Text Features in Referring Image Segmentation: From Object ...
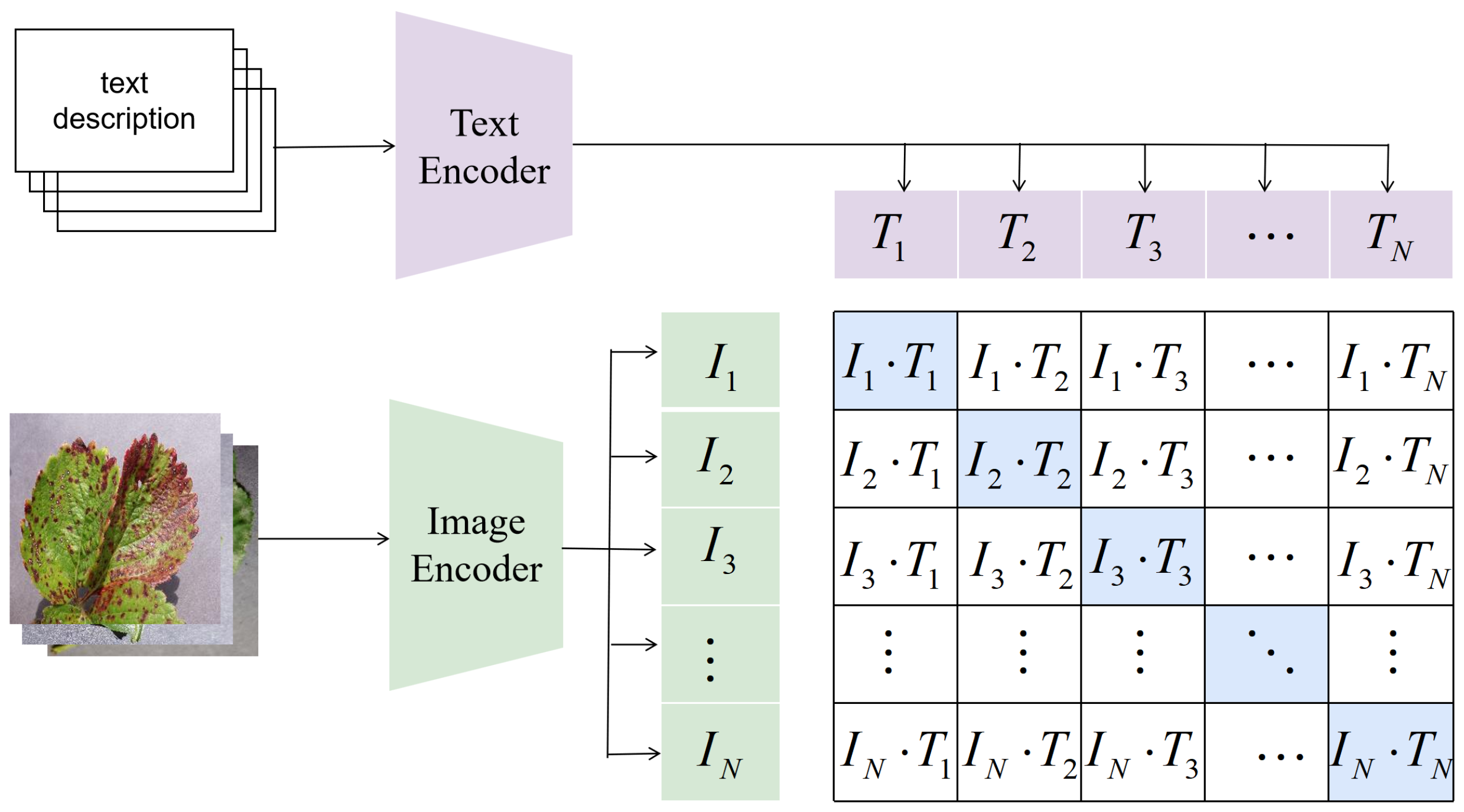
Few-Shot Image Classification of Crop Diseases Based on Vision-Language ...
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary ...
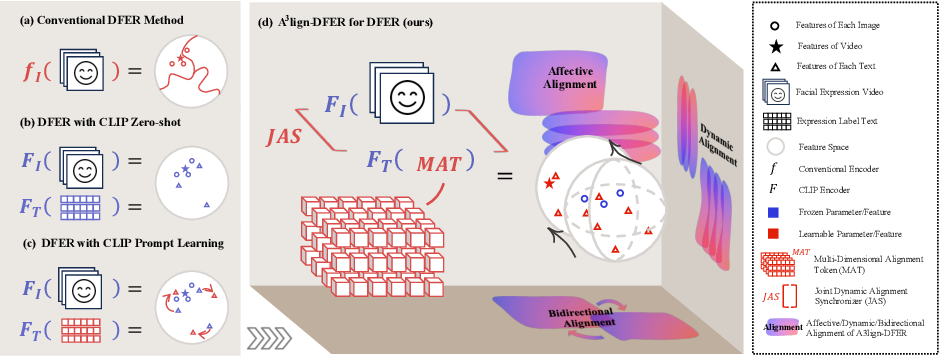
Figure 1 from A3lign-DFER: Pioneering Comprehensive Dynamic Affective ...
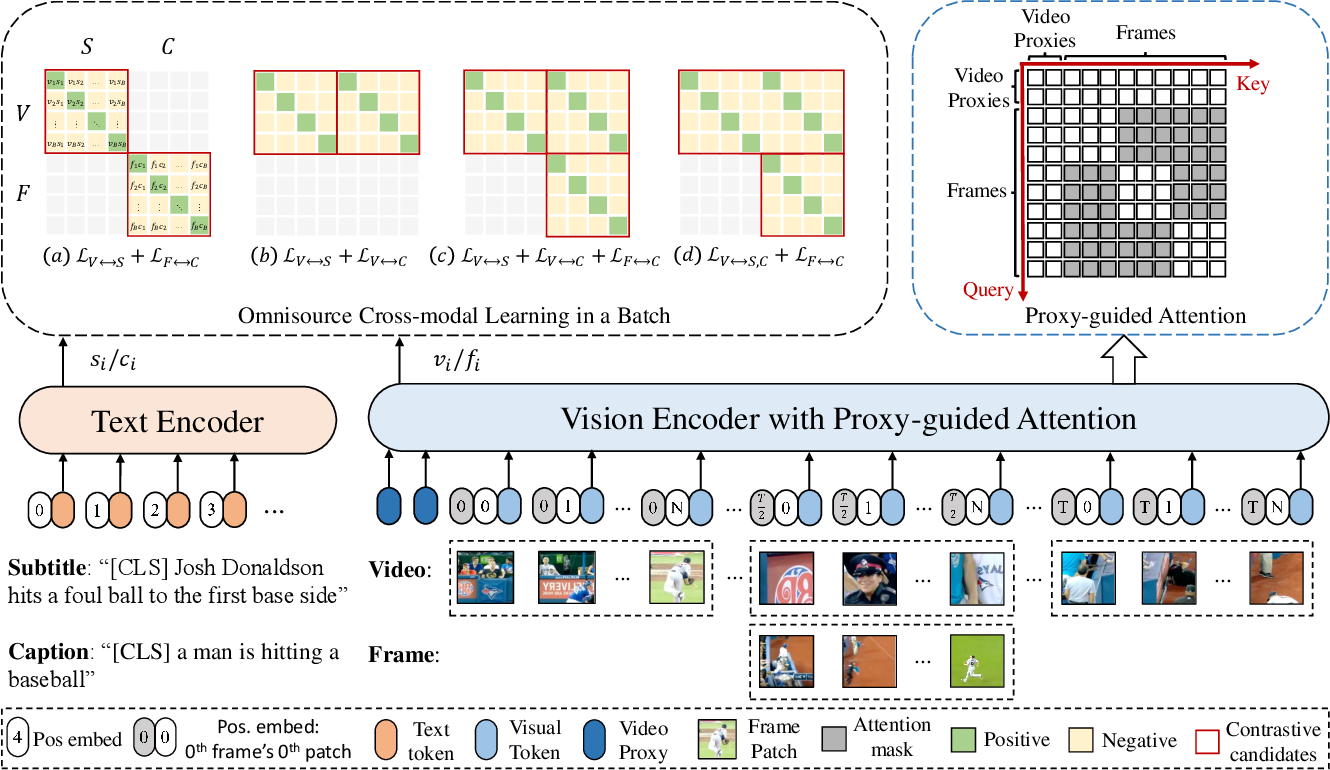
Figure 2 from CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
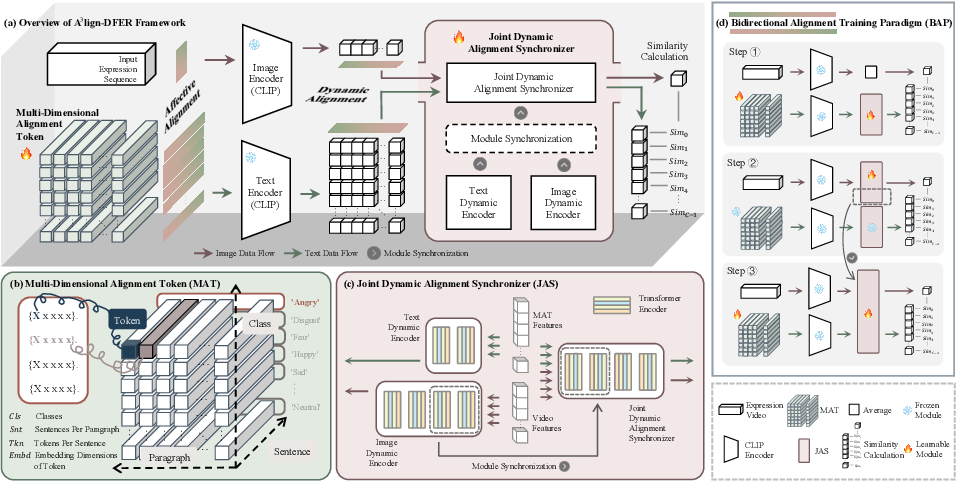
Figure 2 from A3lign-DFER: Pioneering Comprehensive Dynamic Affective ...
CLIP模型全景回顾:视觉-语言预训练模型的演进与展望 - 知乎
CLIP-Clique: Graph-based Correspondence Matching Augmented by Vision ...
GitHub - xuguohai/X-CLIP: An official implementation for "X-CLIP: End ...
GitHub - UnicomAI/HiMo-CLIP: [AAAI 2026 Oral] HiMo-CLIP: Modeling ...
【CLIP系列文章汇总】视觉-语言预训练模型 (VL) - 知乎
Figure 1 from HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity ...
Aman's AI Journal • Primers • Vision Language Models
FG-CLIP: Fine-Grained Visual and Textual Alignment——细粒度视觉与文本对齐_fgclip ...
神器CLIP:连接文本和图像,打造可迁移的视觉模型 - 知乎
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的 ...
UC Berkeley and NYU AI Research Explores the Gap Between the Visual ...
Understanding CLIP: The Powerful AI Model Combining Language and Images ...
详解一篇CLIP应用在语义分割上的论文_clip做语义分割在通用视觉领域-CSDN博客
An example of soft-clipped alignment. There is an insertion in the ...
This AI Paper Introduces Advanced Techniques for Detailed Textual and ...
[2209.06430] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
FG-CLIP/README_en.md at main · 360CVGroup/FG-CLIP · GitHub
ICML 2025 | FG-CLIP:细粒度视觉和文本对齐,解决CLIP的"近视"问题! - 知乎
Paper page - MTA-CLIP: Language-Guided Semantic Segmentation with Mask ...
clip:learning transferable visual models from natural language ...
Fooling Contrastive Language-Image Pre-trained Models with ...
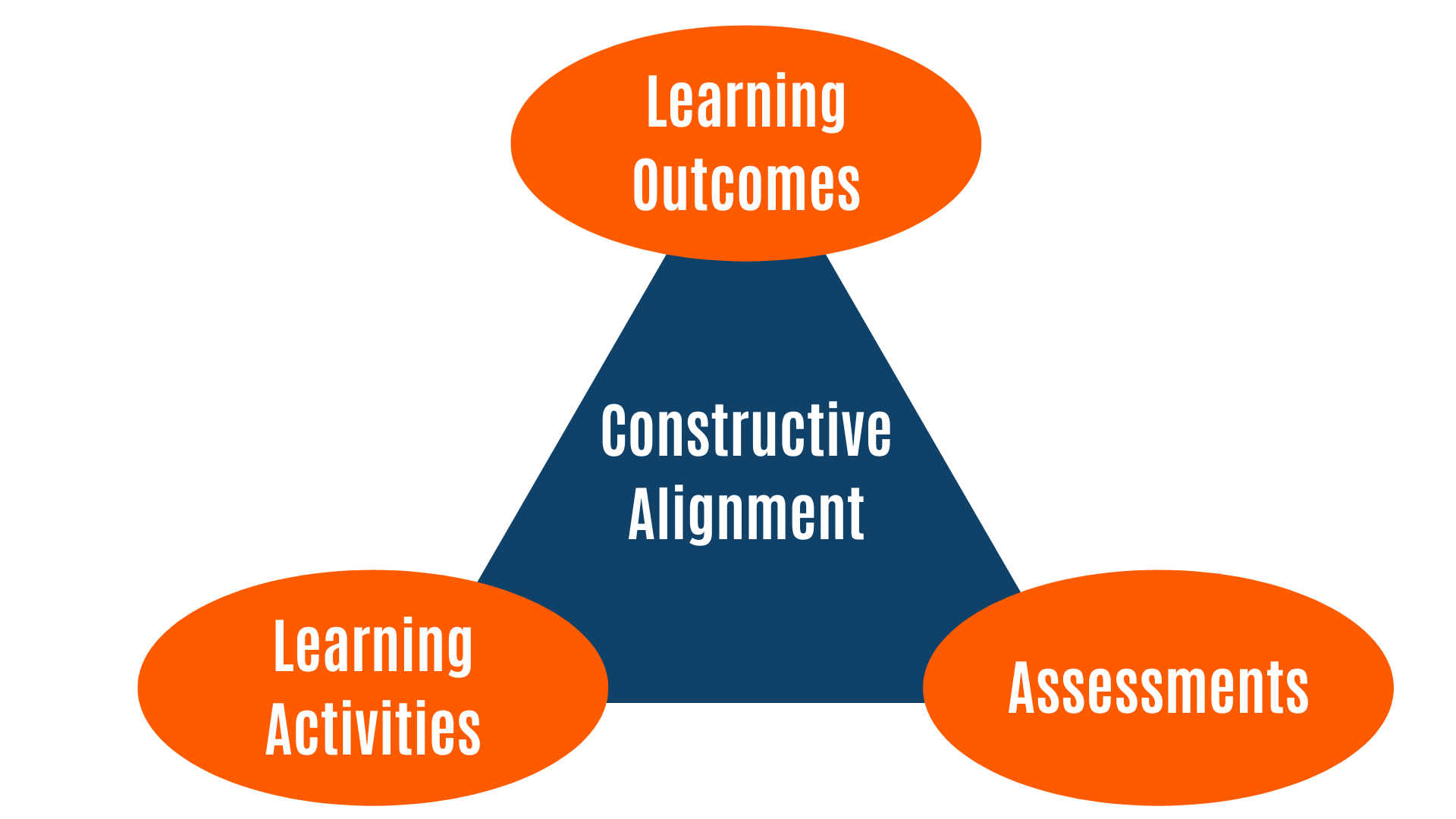
Instructional Design Overview — Latest documentation
GitHub - shaunak27/grain-clip: GRAIN is a new pretraining strategy for ...
(PDF) Gentle-CLIP: Exploring Aligned Semantic In Low-Quality Multimodal ...
[论文评述] Refining CLIP's Spatial Awareness: A Visual-Centric Perspective
ActAlign: Zero-Shot Fine-Grained Video Classification via Language ...











.png)